この記事のトピック
- OpsRamp の機械学習(OpsQ)が、IT チームがインシデントをどのように処理するかを学習して、より正確な優先順位付け、ルーティング、アサインを可能にする方法
- インテリジェント・アラート・エスカレーションの 3つのコンポーネントについて
- ITSM がどのようにしてアラートエスカレーションのための意思決定ツリーの構築を開始するための種となるか
アプリケーション、クラウド環境、ポイント監視ツールの成長を考えると、アラート管理はもはや管理可能なタスクではありません。アラートデータをフィルタリングして意味のあるものにしたり、インシデントをどこにルーティングするかを決定したりするのに多くの時間が費やされています。これらのステップのすべてが、重要な問題の特定と解決を遅らせています。
この記事では、機械学習のインテリジェンスと自動化を通じて、IT アラートに対処するための、より賢明で現代的な方法についてお話ししたいと思います。インテリジェントなアラートエスカレーションのコンセプトは、アラート管理の非効率的な手作業を排除し、オペレータが遅延なくビジネスの重要な問題の調査と解決に集中できるようにする AIOps テクノロジーに依存しています。
インテリジェント・アラート・エスカレーションには、以下の 5つの活動が組み込まれています
- アラート / インシデントルーティングのための一連のポリシーを作成する
- インシデント作成の条件を定義する
- IT サービスマネジメント(ITSM)プラットフォームとの統合
- OpsRamp で継続的な学習を可能にし、意思決定ツリーモデルをトレーニングする
- 未知のイベントの解決にスタッフのワークフローを再集中させる
OpsRamp を使用したインテリジェント・アラート・エスカレーションは、次のようなメリットをもたらします
- チームがイベントストリームの画面を見て指示を求める必要はありません
- ワークフローをシフトして、新しいインシデントに集中できるようにします
- 機械学習(OpsQ)を使用してチームがどのようにインシデントを処理するかを学習し、より正確な自動化を可能にします
- 強化されたインシデントを配信して、調査と解決を改善します
- ITサービスマネジメント(ITSM)ツールとの統合による時間の短縮
- ビジネスレスポンスの向上と連携
始めるには
-
適切なポリシーを選択する
ほとんどの組織はアラートエスカレーションポリシーを持っていますが、数が多すぎたり、優先度が高くないポリシーを持っていたりすることがあります。まず、最大のビジネスサービスリスクに関連する重要なアラートのエスカレーションポリシーを 5~6個以内にすることから始めます。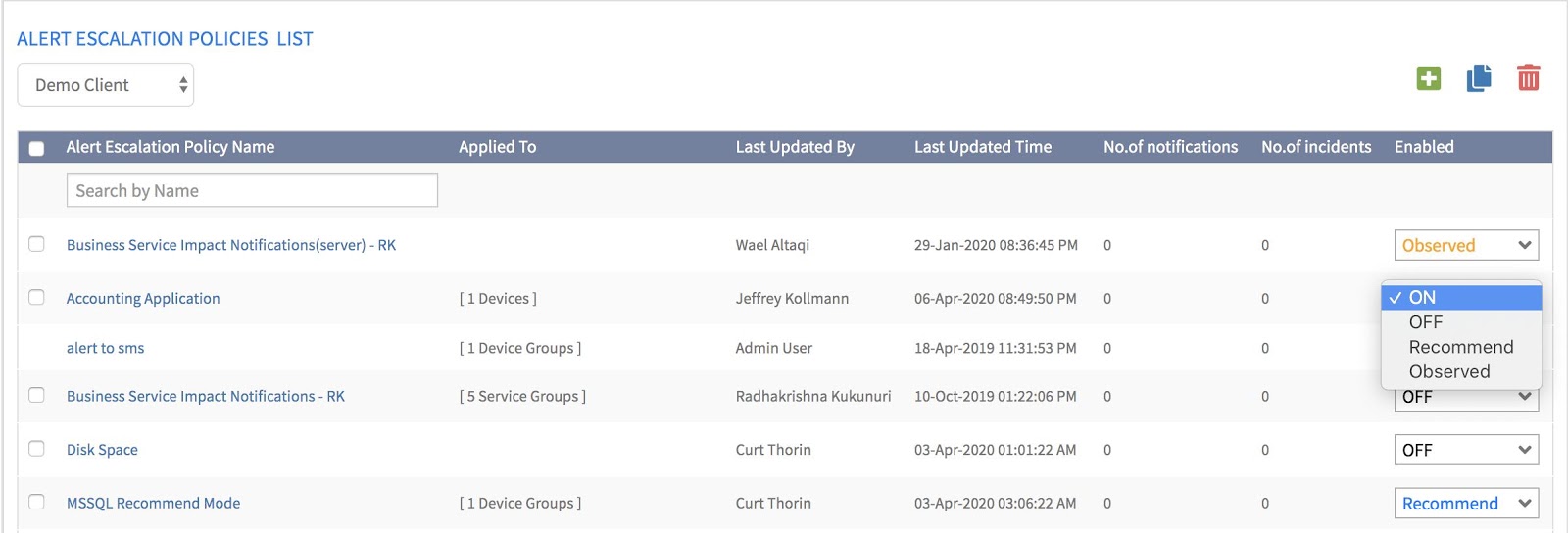
-
アラートからインシデントを作成するための条件を定義する
OpsRamp の機械学習アルゴリズムがそこからプロセスを駆動し、正しいオペレーターにアラートを送信します。OpsRamp には完全なロスター・サポートが含まれているため、アラートを現在勤務中の担当者にルーティングすることができ、時間のかかるテキストや電話で利用可能なエキスパートを探す必要はありません。
注: このプロセスは、OpsRamp がアラートを自動的に重複排除、フィルター処理、相関処理してノイズを低減した後に実行されます。通常、このプロセスにより、企業はアラートの量を 60~80% 削減することができます。
-
ITSM との統合
OpsRamp は、ServiceNow やその他の一般的な ITSM ツールと簡単に統合できます。また、当社の API を使用することで、IT チームはプラットフォームを任意の他の ITSM に接続することができます。まず、ITSM システムから過去のチケット・データをインポートしてコンテキストを取得し、それを種としてアラートのエスカレーション、優先順位付け、ルーティングのためのディシジョン・ツリーの構築を開始することができます。この統合により、ユーザーはサービスデスクシステムと IT インシデント管理システムの間を行き来する必要がなくなります。インシデントは OpsRamp で作成し、ITSM ツールでチケットとして自動的に生成することができます。インシデント・ワークフロー・プロセスの各ステップで、ITSM システムは自動的に最新の情報とステータスで更新されます。これにより、ヘルプデスクの従業員、IT オペレーションスタッフ、および SRE(Site Reliability Engineer)が同じページを共有することができます。また、これは双方向の統合であるため、情報の流れは双方向になり、OpsQ は ITSM システム内で行われたアクションから学習することができます。
-
継続的な学習を可能にして、アラートおよびインシデント管理を改善する
OpsRamp のアラートエスカレーション機能とルーティング機能を使い始めると、システムはベストプラクティスを学習し、後でそれをエミュレートすることができます。これにより、特に一般的で反復可能なイベントについては、多くの時間と労力を節約することができます。これがどのように機能するかを説明するために、最初にイベント管理チームにルーティングされたチケットを考えてみましょう。調査後、SQL DBA L2 チームはそのチケットを優先度の高いものに変更します。次に同様のインシデントが発生した場合、そのインシデントは DBA チームに直接ルーティングされ、適切なナレッジドキュメントが添付されます。これにより、既知のイベントのトリアージに何時間もかかることを回避することができます。
トレーニングを開始するには、OpsRamp の Alert Escalation ポリシーで Continuous Learning を有効にする必要があります。トレーニングファイルを用意し、どの属性(リソース・グループ、クラウド・サブスクリプション、カスタム属性など)を使用してインシデントの決定を駆動するかを注記することができます。また、カラム名のみの空の CSV ファイルを提供することで、既存のアラートおよびインシデント・データから OpsQ にフィールド値を学習させることもできます。すると OpsQ は、過去 3カ月分のアラートおよびインシデントデータからインシデント作成ルールを学習します。学習プロセスは毎月実行され、学習した ML モデルがデータ内の最新のパターンと一致していることを確認します。
-
未知のイベントにスタッフの時間を集中させる
インシデントを発生させるイベントが発生し、その結果が不明な場合は、ITSM の一般的なインシデントキューにルーティングされます。その後、イベント管理チームがインシデントを割り当て、優先順位を付け、ルーティングします。これにより、専門家は、より困難で曖昧な問題にエネルギーを集中させることができます。
次回の記事では、アラートの相関関係について深く掘り下げ、ユーザーをスマートで安全な自動化パスウェイに導くための OpsRamp Observe Mode と Recommend Mode の使用について詳しく説明します。
Written by Chris Bell
本記事は、OpsRamp の Web サイトにて公開されたブログを翻訳して掲載しています。