クラウド・スケール・マネジメントの課題
ワークロードをパブリッククラウドインフラに移行することで、IT 運用チームの日常的な問題の多くを解決します。クラウドを導入することで、CIO(最高情報責任者)はデータセンターの設備管理、キャパシティ利用率の監視、エネルギー消費について心配する必要がなくなりました。しかし、パブリッククラウドサービスには、独自の運用上の課題があります。
- 旧(オンプレ)と新(クラウド)のワークロードを同じレベルの可視性と一貫性で監視するにはどうすればよいか?
- 異なる Amazon Web Services(AWS)上にアプリケーションを構築している場合、Amazon の可用性と耐久性のサービスレベル契約に沿って 99.9% のアップタイムを実現するにはどうすればよいか?
パブリッククラウドサービスの弾力性、一過性、回復力のある性質から、IT チームは可用性とパフォーマンス管理の面でステップアップすることが求められています。クラウドは「常時稼働の可用性」を提供していると思うかもしれませんが、実際にはデータセンターで経験したのと同じように、クラウドインフラは技術的な障害に見舞われています。2017年2月に発生した有名な AWS S3 の障害を含め、ほとんどのパブリッククラウドの障害は人為的なミス(手動処理やコードの不備によるデプロイ)が原因となっています。
クラウドプロバイダーは、問題認識や影響度分析のためのさまざまなモニタリングツールを提供しています。AWS の場合、CloudWatch は、メトリクスの追跡、ログの監視、アラームの生成により、システム全体の健全性とパフォーマンスを追跡するのに役立ちます。Amazon CloudWatch は、あらゆるタイプの AWS ワークロードに対して豊富なモニタリング指標を提供していますが、CloudWatch は実装が難しく、既存のプロセスに組み込むことが困難で、コスト面でも予測がつかないことがあります。
なぜ Amazon CloudWatch はエンドツーエンドの監視のために重労働が必要なのか
AWS プラットフォーム上で複数のアプリケーションを実行している企業であれば、EC2、Lambda、S3、Glacier、VPC、Route 53、RDS、Aurora など、異なる AWS サービスを利用していることが多いでしょう。また、災害復旧のための冗長性を確保し、コンテンツ配信のためのレスポンスタイムを短縮するために、アプリケーションを異なる AWS リージョンでホスティングする必要があるかもしれません。
ここでは、CloudWatch で AWS インフラを監視している間に考慮しなければならない実用的な課題をいくつか紹介します。
-
リージョン固有の設定
グローバルアプリケーションを異なる AWS リージョンでホストしている場合は、各 AWS リージョンごとに CloudWatch モニタリングを個別に設定する必要があります。米国東部(バージニア州)、米国西部(カリフォルニア州)、EU(ロンドン)、アジア太平洋地域(シンガポール)にアプリケーションをデプロイしている場合は、4つの地域すべてで CloudWatch のメトリック、ダッシュボード、アラーム、およびイベントの設定を行う必要があります。また、CloudWatch では、さまざまなワークロードに対して、地域ごとに異なるメトリクスを組み合わせることはできません。
-
手動アラーム設定
まず、アラームポリシーを作成するための AWS リソースのメトリクスを個別に選択し、CloudWatch でアラーム通知を手動で設定する必要があります。手動でスクリプトを作成せずに、既存のワークロードや作成予定のワークロードに CloudWatch のアラーム設定をプッシュする自動化された方法はありません。
-
一般的な通知
CloudWatch では、メールで通知を送信するか、Amazon Simple Notification Service(SNS)や Amazon Simple Queue Service(SQS)に通知を送信するように設定ができます。ただし、AWS リージョンごとに CloudWatch の通知を手動で設定する必要があります。また、CloudWatch の通知を既存のインシデント、問題、変更管理のワークフローとシームレスに統合することはできません。
-
初歩的なアプリケーションのインサイト
Amazon CloudWatch は、エンタープライズアプリケーションを管理するためのアウトオブボックスの監視テンプレートを提供していません。アプリケーションのメトリクスのために高度なログを集約する必要がある場合は、まず CloudWatch エージェントをインストールしてから手動で設定を行う必要があります。
OpsRamp で AWS インスタンスをコントロールする
OpsRamp のマルチテナント SaaS プラットフォームでは、クラウドインフラの一般的な運用プロセス(ディスカバリ、モニタリング、イベント相関、アラート)を拡張でき、DevOps チームに余分な負担をかけることなく、クラウドインフラを拡張できます。OpsRamp で異なるチーム向けに複数のテナントを作成し、各テナントに複数の AWS アカウント、リソース、ポリシーをオンボードできます。また、各テナントに無制限の AWS アカウントを設定でき、プロアクティブな監視と企業全体の AWS リソースの可視性を確保できます。
OpsRamp を使用することで、クラウド上の IT 障害を迅速に検出して処理し、ビジネスに重要な問題に迅速に対処できます。Amazon CloudWatch のメトリクスと OpsRamp のデジタル・オペレーション・コマンドセンターを組み合わせることで、エンドユーザーに影響を与える前に問題を診断して解決できます。
-
リアルタイム分析
CloudWatchのすべてのメトリクスをOpsRampにインジェストして保存することで、クラウド・アプリケーションの可用性と健全性について統合されたリアルタイムのインサイトが得られます。
-
即時の可視性
CloudWatch および CloudTrail のログとアラートを API 経由で OpsRamp にストリーム配信。CloudWatch メトリクスの OpsRamp API クエリの総数に制限はありません。
-
データの保持
CloudWatch メトリクスデータ全体を OpsRamp に 12ヶ月間保持します。また、コンプライアンス目的で CloudWatch データの保持期間を延長することもできます。
-
包括的なアプリケーションモニタリング
基本的な EC2 CloudWatch メトリクスを、エンタープライズアプリケーション向けの OpsRamp のネイティブモニタリング機能で補完します。
-
効率的なクラウド運用
OpsRamp の自動管理フレームワークを使用して、クラウド運用を合理化し、インシデントの修復を規模に応じて処理します。
OpsRamp は、管理する AWS リソースの数に応じたシンプルで透明性の高い価格設定を提供します。リソースベースの価格設定には、測定基準、アラーム、イベント、ダッシュボードなどの個別の制限はなく、OpsRamp のプラットフォーム機能のすべてが含まれています。
OpsRamp で AWS の CloudWatch 機能を拡張
OpsRamp で AWS リソースを効果的に監視することで、クラウドのワークロードパフォーマンスをリアルタイムに追跡し、停止を防ぎます。パブリッククラウドの消費の可視化を推進し、すべてのクラウドサービスの単一の真実のソースを実現できます。Amazon CloudWatch のメトリクスと OpsRamp のハイブリッドインフラ管理プラットフォームを組み合わせるメリットをご紹介します。
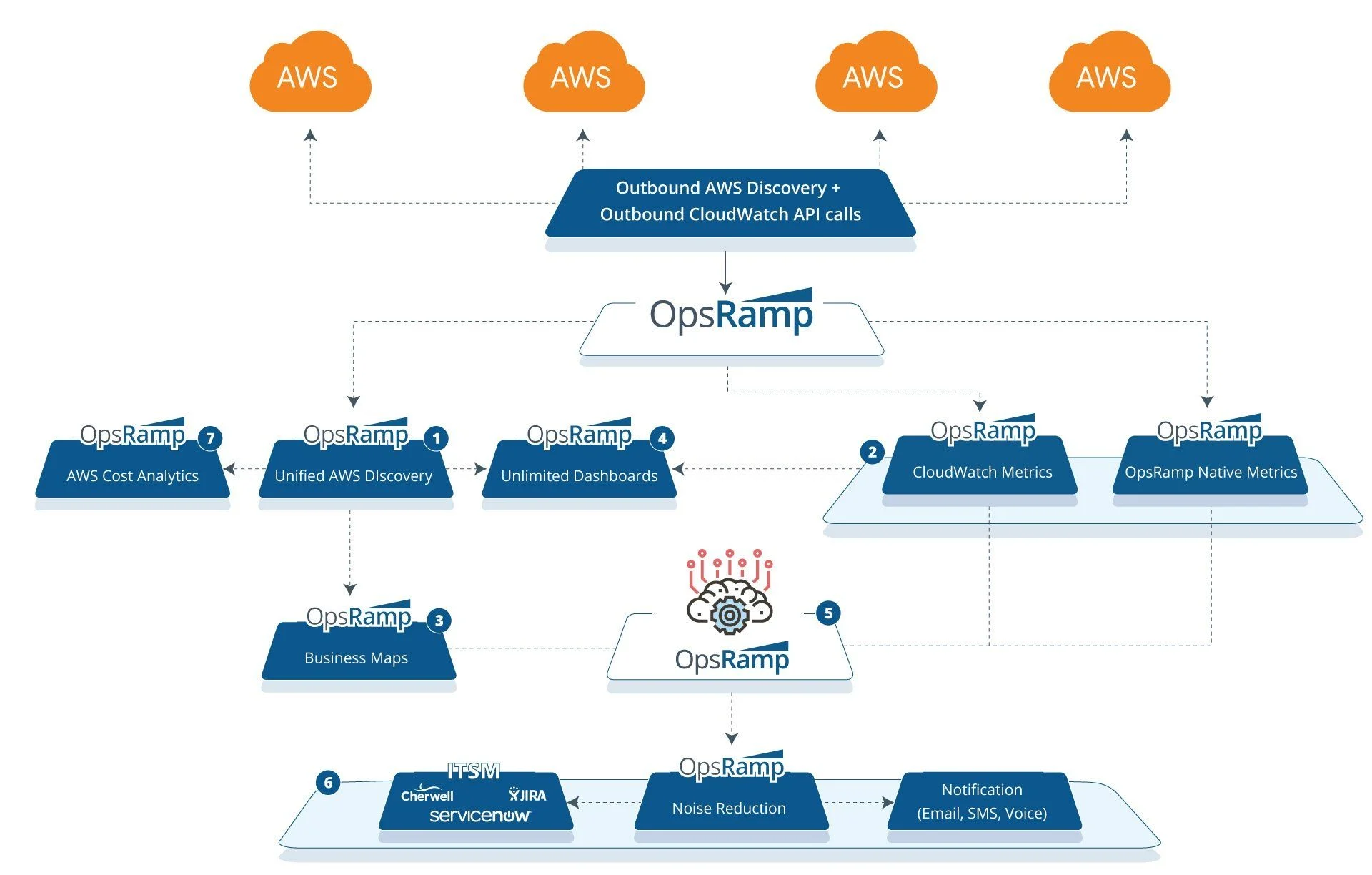 図1 - OpsRamp を使用して、AWS スタック全体を単一の場所で管理
図1 - OpsRamp を使用して、AWS スタック全体を単一の場所で管理
-
ユニファイド・ディスカバリー
すべての AWS アカウントを OpsRamp にオンボードし、クラウドインフラを動的に検出します。すべての CloudWatch および CloudTrail キューを OpsRamp にストリーム配信し、クラウドインフラをプロアクティブに可視化します。
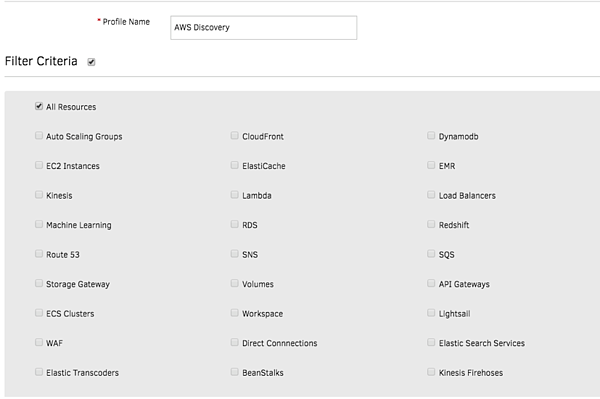
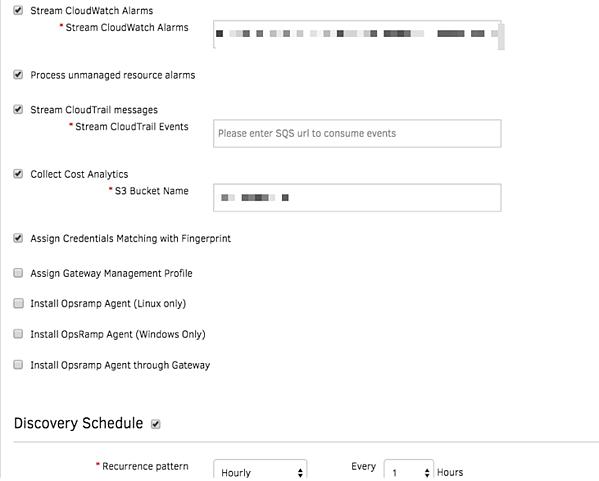 図2 - ユニファイド・サービス・ディスカバリーを使用したダイナミック AWS リソースの検出とオンボード
図2 - ユニファイド・サービス・ディスカバリーを使用したダイナミック AWS リソースの検出とオンボード
-
スマート管理ポリシー
OpsRamp のポリシーを使用して、CloudWatch のメトリクスを自動的に収集し、OpsRamp エージェントが収集したメトリクスと組み合わせることができます。OpsRamp のアプリケーションモニターは、アプリケーションの健全性とパフォーマンスに適切なコンテキストを提供し、お客様のクラウド資産の包括的なビューを提供します。
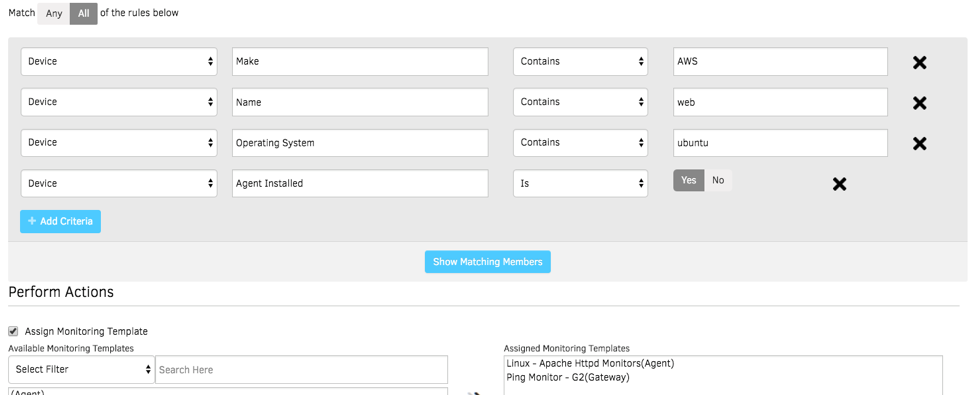
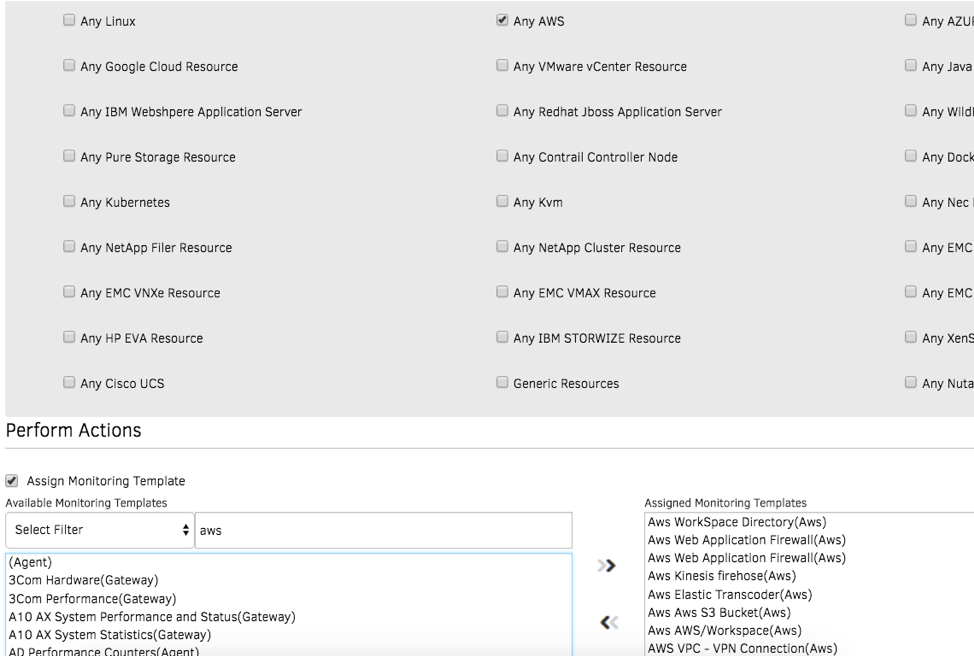 図3 - スマートポリシーでクラウドインフラのアップタイムとパフォーマンスを管理
図3 - スマートポリシーでクラウドインフラのアップタイムとパフォーマンスを管理
-
サービス中心の可視性
AWS リソースのサービスマップを構築することで、目に見える可視性を実現し、IT 停止時の影響分析を迅速に行うことができます。メトリクスとアラートをサービスマップビューに統合することで、ビジネスに不可欠なサービスをより良く管理できます。
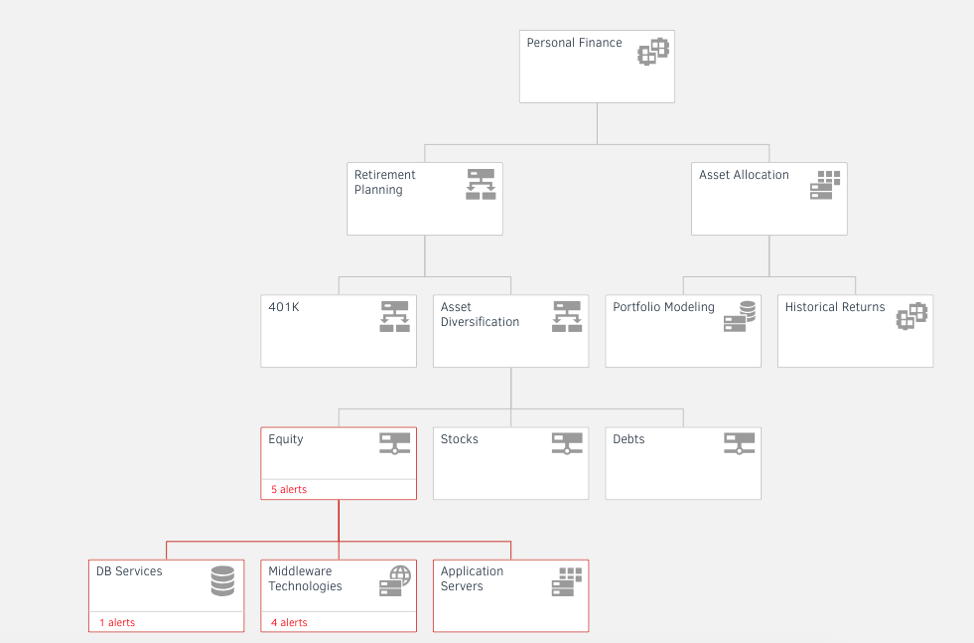 図4 - サービスマップでアプリケーションと AWS リソースの依存関係を追跡
図4 - サービスマップでアプリケーションと AWS リソースの依存関係を追跡
-
リアルタイムダッシュボード
OpsRamp で無制限のダッシュボードを作成し、CloudWatch のすべてのメトリクスとログに関連するパフォーマンスのインサイトを抽出します。カスタマイズ可能な役割ベースのダッシュボードを使用して、クラウドサービスの可視性を確保し、インサイトに至るまでの時間を短縮します。
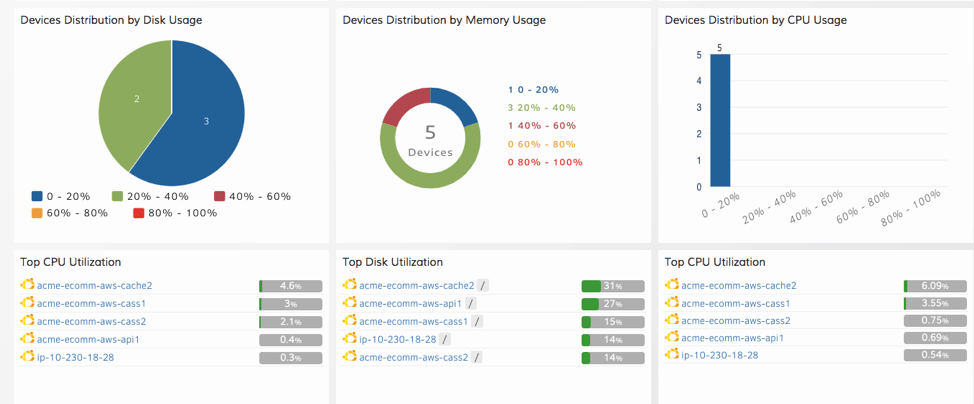 図5 - より優れた可視化と分析で AWS インフラを管理
図5 - より優れた可視化と分析で AWS インフラを管理
-
推論エンジン
AIOps 推論エンジンは、CloudWatch から生のイベントとアラートを取り込み、高度な分析とトポロジーベースのイベント相関を使用して IT インシデントの根本原因を特定するのに役立ちます。アラートのノイズを減らすことができるだけでなく、適切なコンテキストと自信を持って IT の停止をトラブルシューティングできます。
-
アラート管理
ターゲットを絞ったルーティングを使用して、コンテキストを反映したアラート通知をオンコールのオペレータに送信します。電子メール、音声、テキスト、チャットなど、さまざまな通信チャネルを使用して通知をプッシュできます。何よりも優れているのは、サービスデスクでインシデントを作成し、堅牢な ITSM ツールとの統合で解決まで管理することです。
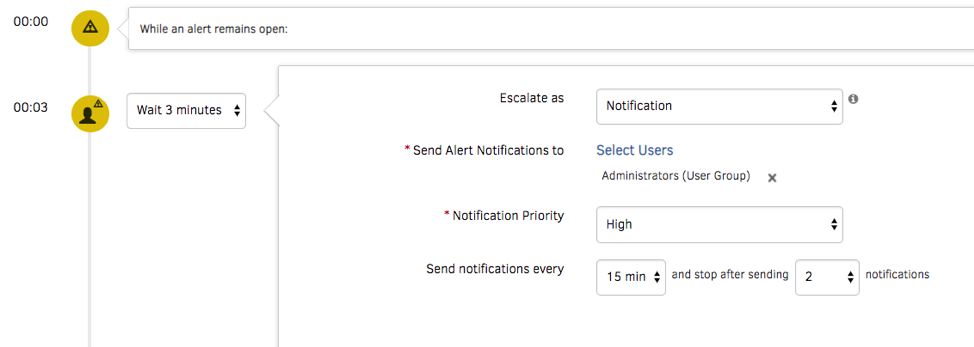
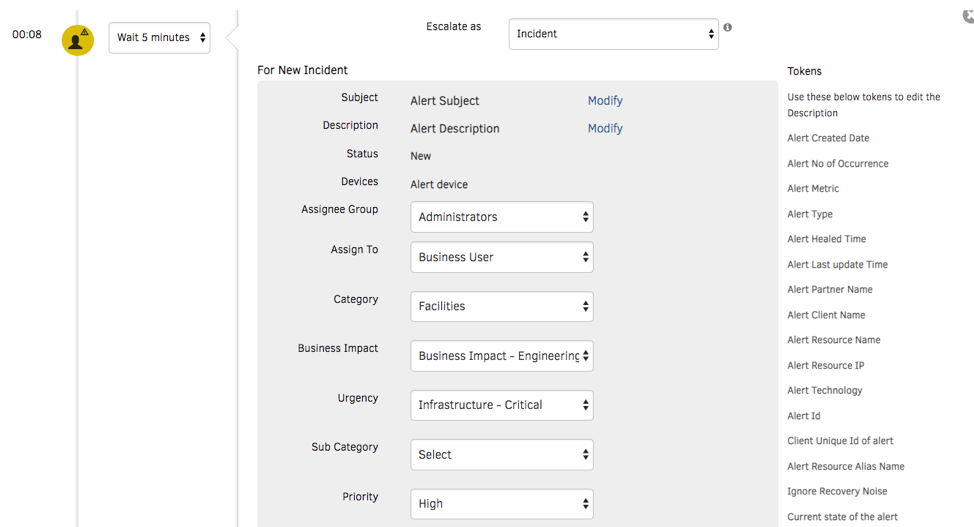
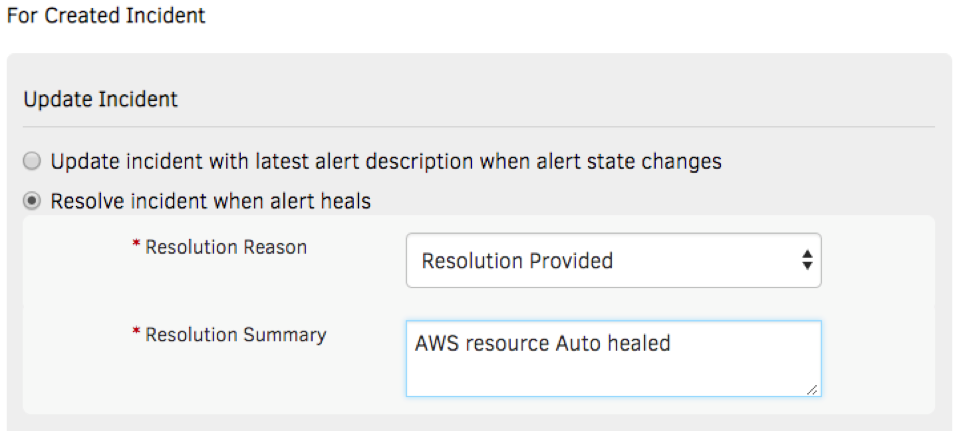 図6 - ジャストインタイムのアラート通知でサービスを迅速に復旧
図6 - ジャストインタイムのアラート通知でサービスを迅速に復旧
-
コストトレンドと予算ポリシー
OpsRampは、AWS S3 のコストバケットから直接コストデータを消費するため、最新のコストインサイトにアクセスできます。Cloud Cost Trends ウィジェットは、アカウント、リージョン、AWS タグ、リソースタイプなどでコストデータを細かく分けられます。OpsRamp に予算ポリシーを実装することで、クラウドの支出が指定した予算のしきい値を超えた場合に警告やクリティカルアラームとして機能します。

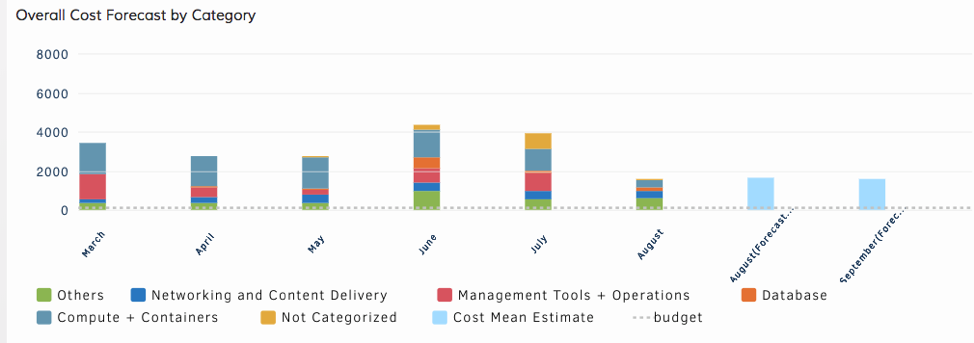 図6 - AWS 資産全体のコストと支出のインサイトに一箇所でアクセス
図6 - AWS 資産全体のコストと支出のインサイトに一箇所でアクセス
