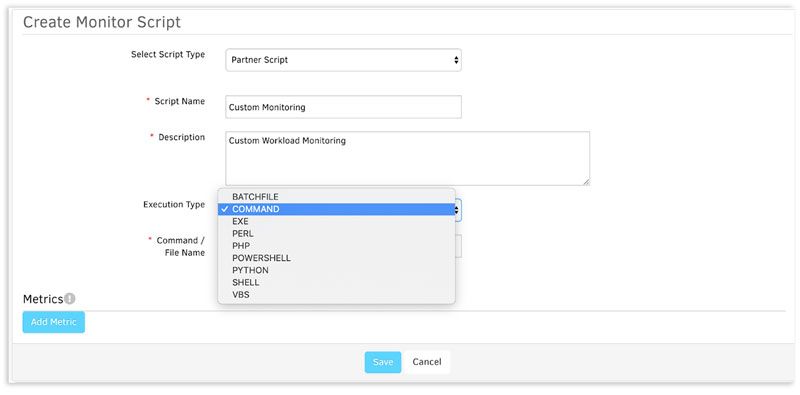
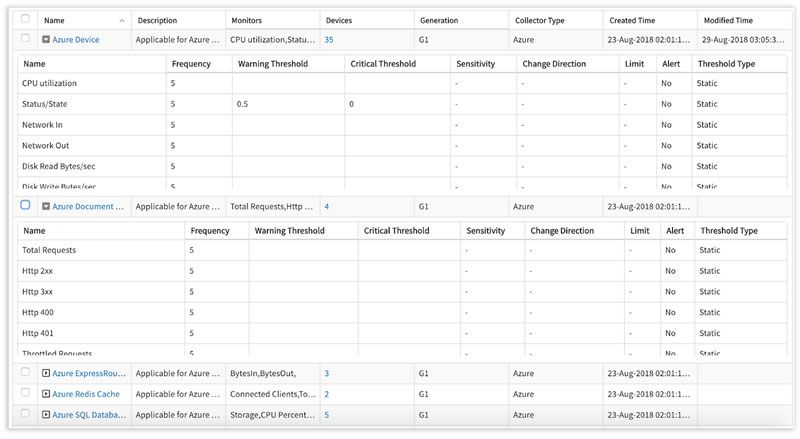
IT 技術・サービスの進化に、迅速に追従できる SaaS

常に最新
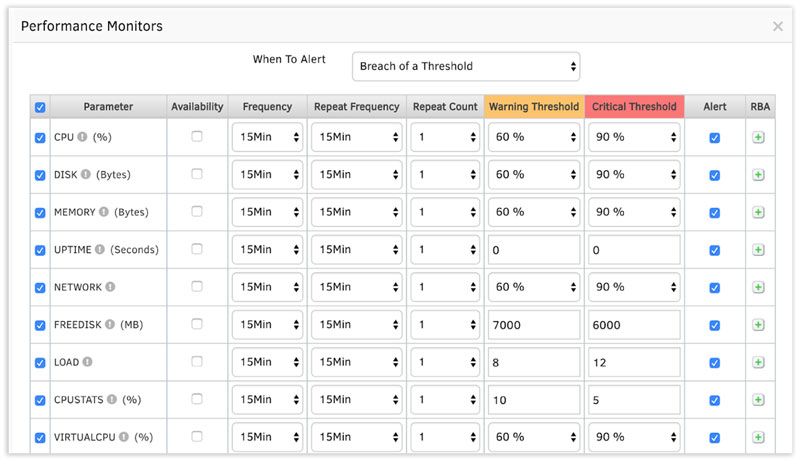
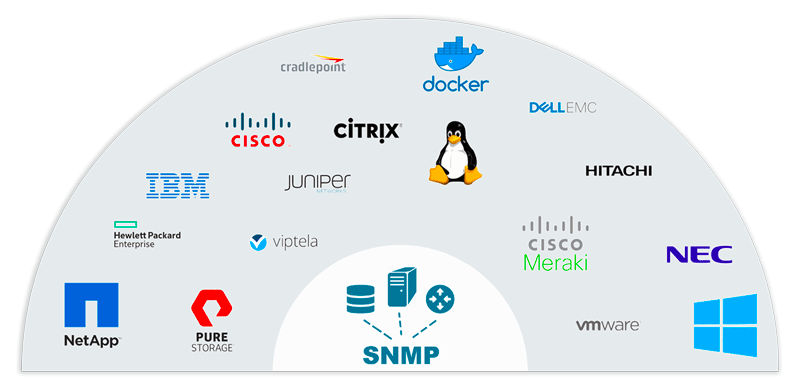
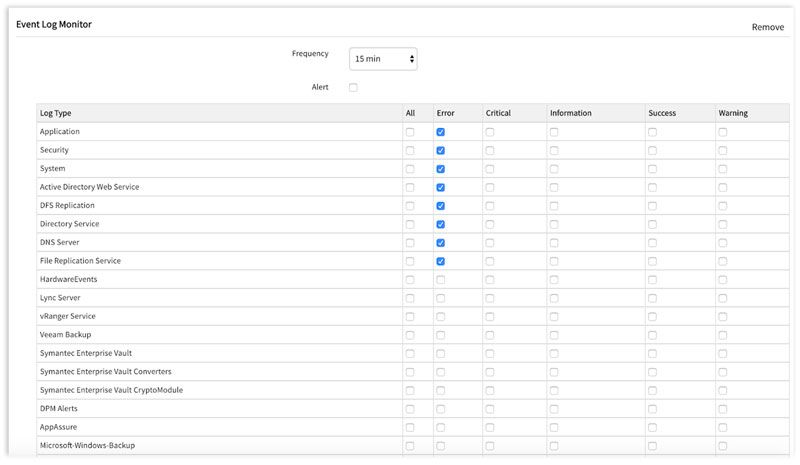
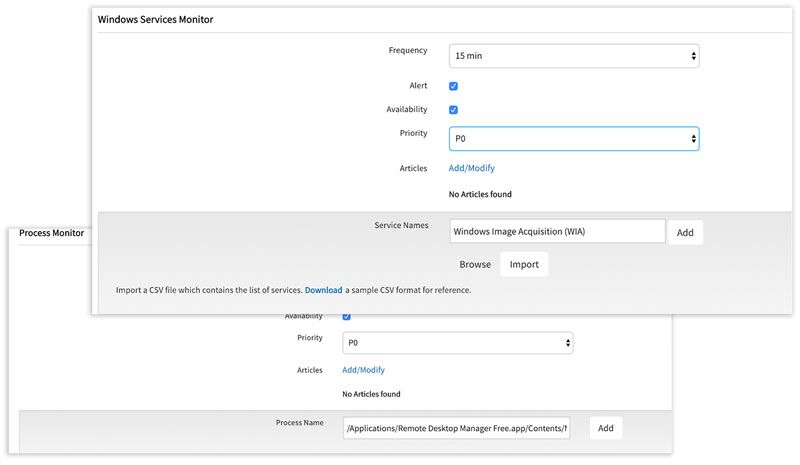
運用管理対象となる IT リソースは、日々進化。OpsRamp は SaaS 型だから、企業が導入している IT 技術・サービス、トレンドの進化と共にリアルタイムで機能拡張されていきます。

スケーラビリティ
企業が管理する IT リソースから出力されるデータは、3V(Volume、Velocity、Variety)の特徴を持ち、まさにビッグデータです。今後ますますこの流れは加速していき、IT 運用監視のプラットフォームには、3V に対応できるスケーラビリティが要求されます。 SaaS 型のプラットフォームでは、こうした高い負荷に対しても柔軟に対応できます。